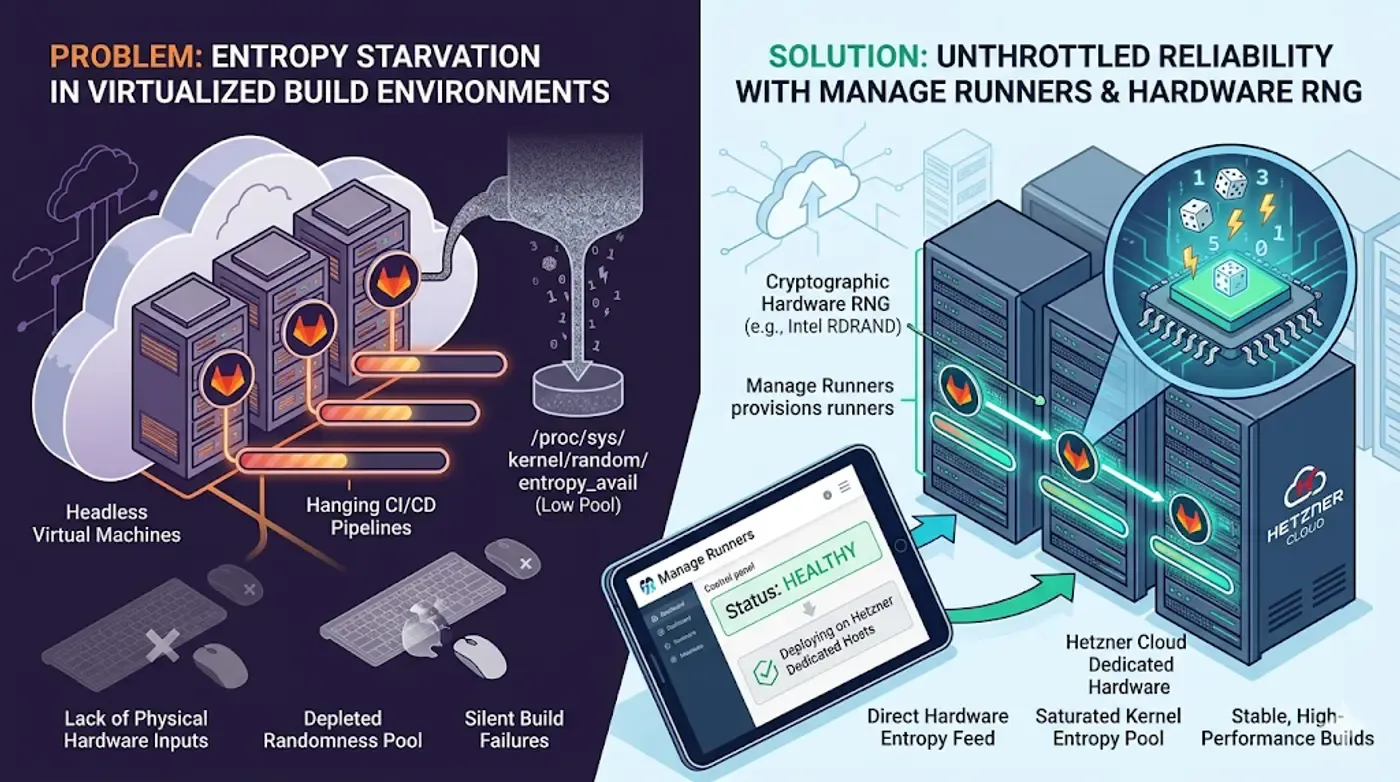
When automated pipeline jobs hang indefinitely without throwing a clear stack trace, engineering teams usually blame flaky testing frameworks or memory leaks. Yet, deep within highly virtualized environments, a silent infrastructure bottleneck frequently targets system reliability: entropy starvation. When parallel container jobs simultaneously request random numbers for secure handshakes, token compilation, or key generation, the host's pool of randomness can dry up, driving critical compilation steps into a permanent freeze.
1. Under the Hood: The Mechanics of Kernel Entropy
To build cryptographic security and maintain runtime consistency, the Linux kernel relies on an internal entropy pool populated by random environmental noise (such as hardware interrupts, storage access timing, and network packet arrivals). The kernel exposes this data through interfaces like /dev/random and /dev/urandom.
When executing hundreds of isolated pipelines inside dense virtual machines, this noise disappears. Headless virtual instances have no physical keyboards, mice, or direct disk interrupts to seed the random number generator (RNG). When parallel test scripts dynamically generate temporary secrets or establish TLS tunnels, they pull from a pool that depletes faster than it can refresh, stalling processes as they wait for the kernel to generate new random bits.
2. The Architectural Cure: Cryptographic Hardware
Resolving this virtualization bottleneck requires shifting from software-simulated entropy generation to hardware-assisted solutions. Modern physical processors include dedicated cryptographic hardware subsystems such as Intel's Secure Key (RDRAND) or AMD's hardware random number generator implementations.
These on-chip components leverage thermal noise to stream high-entropy random numbers directly to the hypervisor at the instruction layer. When a virtual machine configuration is structurally optimized to pass these hardware instructions directly down to the guest kernel, the system's entropy pool remains permanently saturated, instantly safeguarding your build engine's stability.
3. Diagnostic Blueprint: Auditing Your Fleet's Available Entropy
You can immediately audit your existing build farm nodes to evaluate if low entropy is undermining your system reliability. Execute the following commands during a peak concurrent build window to inspect your kernel parameters:
# Check the current available entropy pool size (traditionally measured in bits)
echo "=== Available Entropy Pool ==="
cat /proc/sys/kernel/random/entropy_avail
# Inspect the active random number generator source feeding the kernel
echo "=== Available Hardware RNG Sources ==="
cat /sys/devices/virtual/misc/hw_random/rng_availableNote: If entropy_avail routinely drops below 256 bits during simultaneous testing cycles, your processes are highly susceptible to resource-starvation timeouts.
4. Manage Runners: Effortless, High-Performance Build Fleets
Manually tuning kernel modules, passing CPU hardware flags through custom hypervisor scripts, and maintaining distributed virtual hosts generates immense DevOps toil. Manage Runners provides a centralized, streamlined platform to deploy and scale dedicated GitLab runners on Hetzner Cloud without the architectural overhead.
Our platform eliminates infrastructure-level resource exhaustion by hosting your build fleet on premium, dedicated infrastructure layers:
- Under 3 Minutes to Active: Spin up identical, hardened runner virtual machines dynamically using a modern dashboard. Choose custom execution specifications (Docker, Docker-In-Docker, or Shell) perfectly aligned with your resource profiles.
- Deterministic Isolation: Every automated runner receives a unique Static IP address, making it simple to restrict target environments through secure whitelists.
- Hardened Security Posture: Automatically assign Hetzner Firewalls to your instances by mapping environment labels directly through our control plane.
- Absolute Code Autonomy: Built to be fully GDPR compliant, your code stays safely inside your own EU-based Hetzner account (Germany/Finland). Crucially, Manage Runners maintains no SSH access to your runner VMs, ensuring total privacy.
By moving your workflows to unthrottled Hetzner hardware and utilizing our native precision scheduling to automatically sleep runners during idle off-hours, engineering teams routinely slash standard managed infrastructure costs by up to 80% while restoring uncompromised performance to their delivery engine.
5. Conclusion
Mysterious execution timeouts are a symptom of underlying resource starvation, not an inevitable cost of continuous integration. By routing your automated build frameworks onto dedicated computing paths with solid hardware backup, you eliminate the entropy bottleneck and secure a stable, predictable path toward rapid product deployment.
Ready to protect your pipelines from silent kernel freezes? [Secure your System Reliability with Manage Runners] and experience uncompromised execution speeds on Hetzner Cloud.