In modern continuous integration, engineering teams invest heavily in tuning application code, yet many wonder why their pipelines still drag. The culprit is rarely the test suite itself; it’s the underlying storage architecture. While sharing build assets over Network-Attached Storage (NAS) or Network File Systems (NFS) seems convenient for cross-worker persistence, it acts as a silent killer for decompression speeds. To build a truly elite build caching strategy, DevOps engineers must move away from network-bound filesystems and address the real enemy of pipeline velocity: the infrastructure I/O bottleneck.
1. The Anatomy of Cache Decompression
When a CI/CD pipeline executes a job, one of its initial phases is pulling the cache typically a compressed archive (such as a .tar.gz or .zip file) containing essential project dependencies like node_modules, .cargo/registry, or .m2/repository.
Extracting these archives doesn't just demand raw CPU compute; it requires creating thousands of tiny files and nested directories sequentially. If your runner workspace is backed by network-attached storage, each individual file creation triggers an independent network round-trip to update file descriptors and metadata tables on the remote storage array.
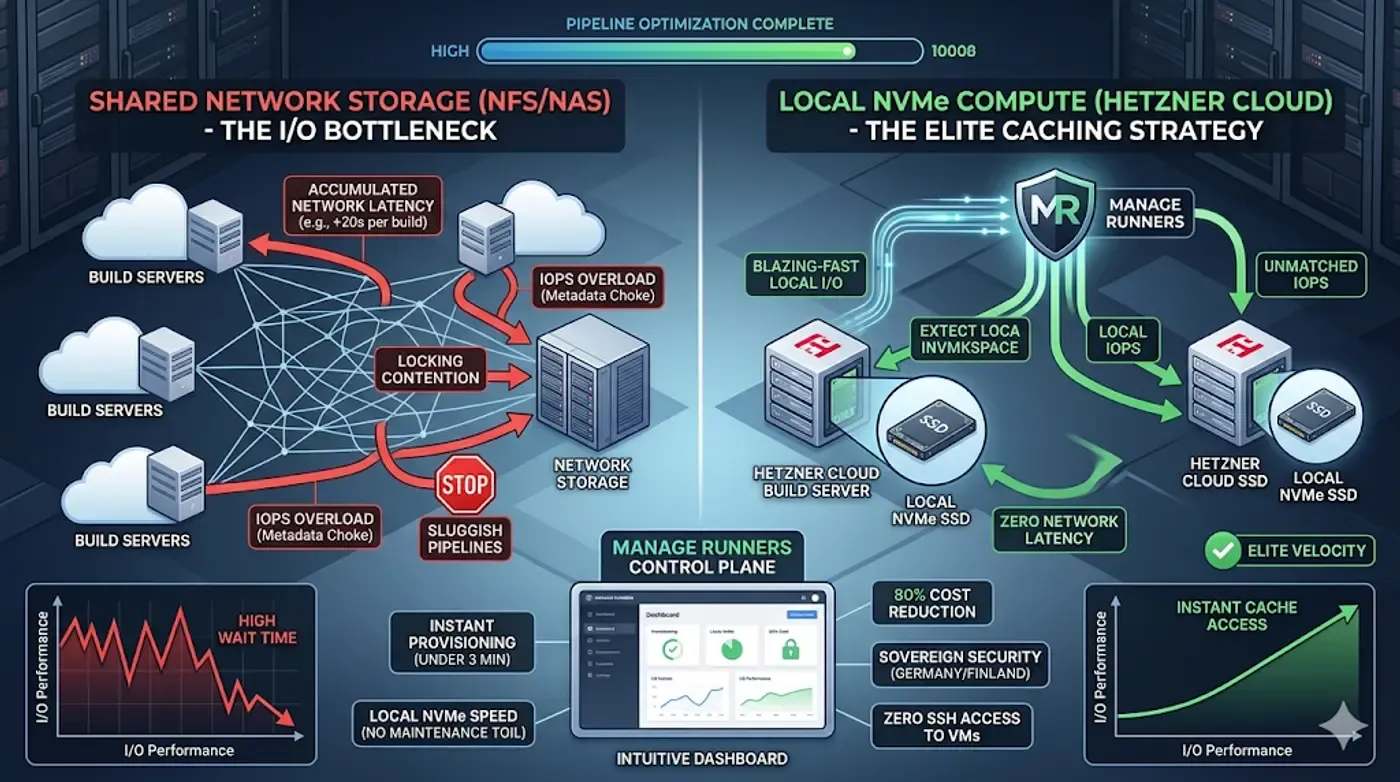
2. Why NAS/NFS Introduces a Severe I/O Bottleneck
Network-attached filesystems are fundamentally designed for the throughput of large, continuous file streams. They choke on the high-frequency metadata operations required by software compilation and dependency extraction. This architectural mismatch creates a crippling I/O bottleneck due to three core factors:
- IOPS Overload: NFS shares struggle with high Input/Output Operations Per Second (IOPS) when dealing with random, small-file write tasks.
- Accumulated Network Latency: Even on a dedicated gigabit local network, adding just 0.5 milliseconds of latency per file operation scales poorly. Across a repository with 40,000 small dependency files, network wait time alone adds over 20 seconds of dead time to the step.
- Locking Contention: When multiple parallel runner nodes attempt to read or modify overlapping directories on a shared network mount, distributed file-locking mechanisms pull the CPU execution queue into a dead stop.
3. Designing a High-Performance Build Caching Strategy
An optimal build caching strategy dictates that the active build workspace must always reside on high-speed, local non-volatile memory (NVMe) solid-state storage directly attached to the runner’s physical hypervisor.
# High-Performance Cache Extraction Blueprint
# Ensure extraction happens entirely within a local NVMe scratch directory
TIME_START=$(date +%s)
# Extracting locally bypasses network metadata overhead
tar -xzf /local/cache/dependencies.tar.gz -C /mnt/nvme-scratch/workspace/
TIME_END=$(date +%s)
echo "Cache unpacked locally onto NVMe in $(($TIME_END - $TIME_START)) seconds."By siloing the cache extraction layer to local scratch space, you shift the workload from a network-bound system to a pure local PCIe bus architecture, completely removing network transport latencies from the compilation loop.
4. Manage Runners: Local NVMe Speed Without Maintenance
Implementing isolated, local-storage runner fleets manually across distributed infrastructure introduces massive configuration toil. Manage Runners provides a centralized, automated control plane to deploy and scale high-performance GitLab runners on Hetzner Cloud without the DevOps maintenance overhead.
- Break the I/O Bottleneck: Instantly provision runners on Hetzner Cloud's high-performance server instances equipped with blazing-fast local storage.
- Under 3 Minutes to Active: Spin up or scale identical runner nodes tailored with custom execution specifications (Docker, Docker-In-Docker, or Shell) straight from a glassmorphism-inspired UI.
- 80% Cost Reduction: Reclaim your CI/CD budget. Pay Hetzner's low compute prices directly with zero markup, and use our native precision scheduling to automatically pause runners during idle off-hours.
- Sovereign Security Posture: Run all workloads within your own GDPR-compliant Hetzner account (Germany/Finland). For uncompromised code privacy, Manage Runners has no SSH access to your runner VMs.
5. Conclusion
A fast pipeline requires localized compute power. Eliminating network-attached storage architectures from your compilation paths is the single most impactful upgrade you can introduce to your build caching strategy.
Ready to eliminate pipeline wait states? [Optimize your Build Caching Strategy with Manage Runners] and unlock true local NVMe performance on Hetzner Cloud.