In 2026, a "down" pipeline is more than just a bottleneck; it’s a total halt to innovation. As development teams become globally distributed, the infrastructure supporting them must be bulletproof. Achieving true high availability requires moving beyond the "one server, one region" mindset. By architecting a multi-region runner fleet, organizations ensure that their code-to-production journey is never interrupted by localized outages or regional latency.
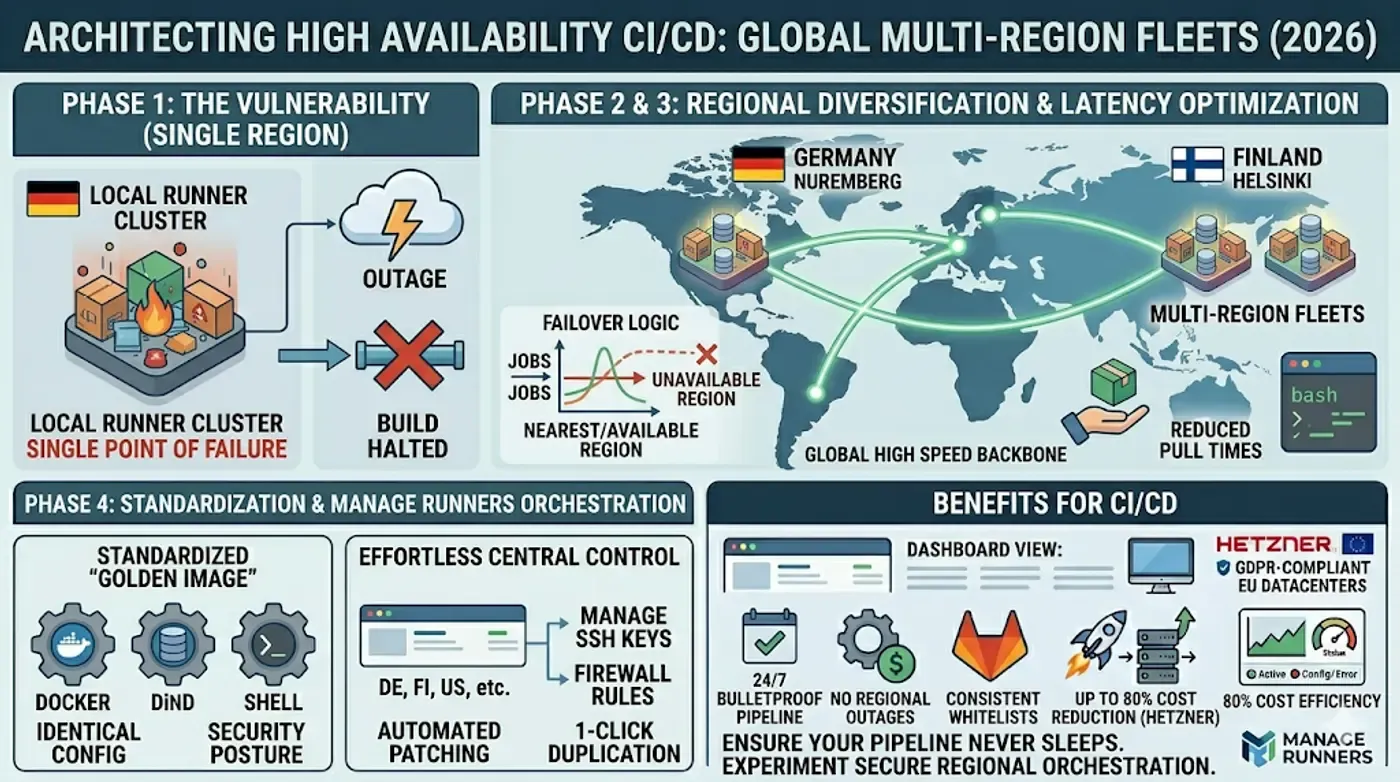
1. Identifying the Single-Region Vulnerability
Most DevOps teams treat their runners as secondary infrastructure. They host them in a single data center, often in the same region as their primary Git provider. This creates a catastrophic single point of failure. If that region experiences a power event or routing issue, your entire CI/CD lifecycle "sleeps." True high availability starts by assuming your primary region will fail and building the redundancy to handle it.
2. Regional Diversification (Germany & Finland)
For teams leveraging the EU's strict data sovereignty laws, Hetzner Cloud offers a unique advantage. Deploying a fleet across both Germany (Falkenstein/Nuremberg) and Finland (Helsinki) provides a robust hedge against regional downtime.
- Geographic Data: Use regional location data to ensure your runners are physically separated.
- Failover Logic: Configure your Git provider to distribute jobs across multiple runner tags representing different geographic zones.
3. Optimizing for Global Connectivity
Latency is the silent killer of build speed. In 2026, the high speed internet availability within tier-1 data centers is what allows for rapid artifact transfer and "burst" scaling. When your runner fleet is geographically distributed, you can route jobs to the node closest to your container registry, significantly reducing "pull" times.
# Example: Labeling runners by region for high availability routing
# Use these labels to direct specific jobs during regional maintenance
hetzner-cli server add-label runner-01 region=hel1
hetzner-cli server add-label runner-02 region=nbg14. Standardizing with a Centralized Control Plane
The biggest hurdle to multi-region setups is the administrative "toil." Managing SSH keys, firewall rules, and OS updates across different zones manually is a recipe for configuration drift. To maintain high availability, your fleet must be standardized. Every runner, regardless of location, should operate as a "Golden Image" identical in executor type (Docker, DinD, or Shell) and security posture.
5. Manage Runners: The High Availability Orchestrator
Manage Runners was built for teams that cannot afford a "sleeping" pipeline. We provide the effortless orchestration layer needed to manage a global fleet on Hetzner Cloud without the DevOps overhead.
With Manage Runners, you can spin up hardened runners across Hetzner’s EU-based data centers instantly. Every runner gets a Static IP address, ensuring your deployment whitelists remain consistent across your fleet. We ensure your data stays sovereign and secure; Manage Runners has no SSH access to your VMs, keeping your source code truly private.
By utilizing our native scheduling to manage regional uptime and leveraging the inherent high speed internet availability of Hetzner’s backbone, you get a 24/7 global build fleet at a fraction of the cost of managed solutions.
6. Conclusion
Redundancy is the only path to reliability. By decentralizing your compute power and moving to a multi-region model, you protect your team's velocity against the unpredictable.
Ready to ensure your pipeline never sleeps? [Deploy your High Availability Runner Fleet with Manage Runners] and experience the power of automated regional orchestration.