When optimizing long-running test execution paths, platform engineers naturally inspect database queries or disk bottlenecks. However, when highly concurrent test loops or compilation tasks scale up on deep virtualized instances, performance drops can stem from a deeper hardware layer. Data fragmentation inside your test code can constantly clear your processor's L1, L2, and L3 CPU cache. Resolving these micro-architectural slowdowns requires low-level performance tuning to design cache-friendly code pathways and align software loops directly with your runtime hardware.
1. The Micro-Architectural Tax: Understanding Cache Misses
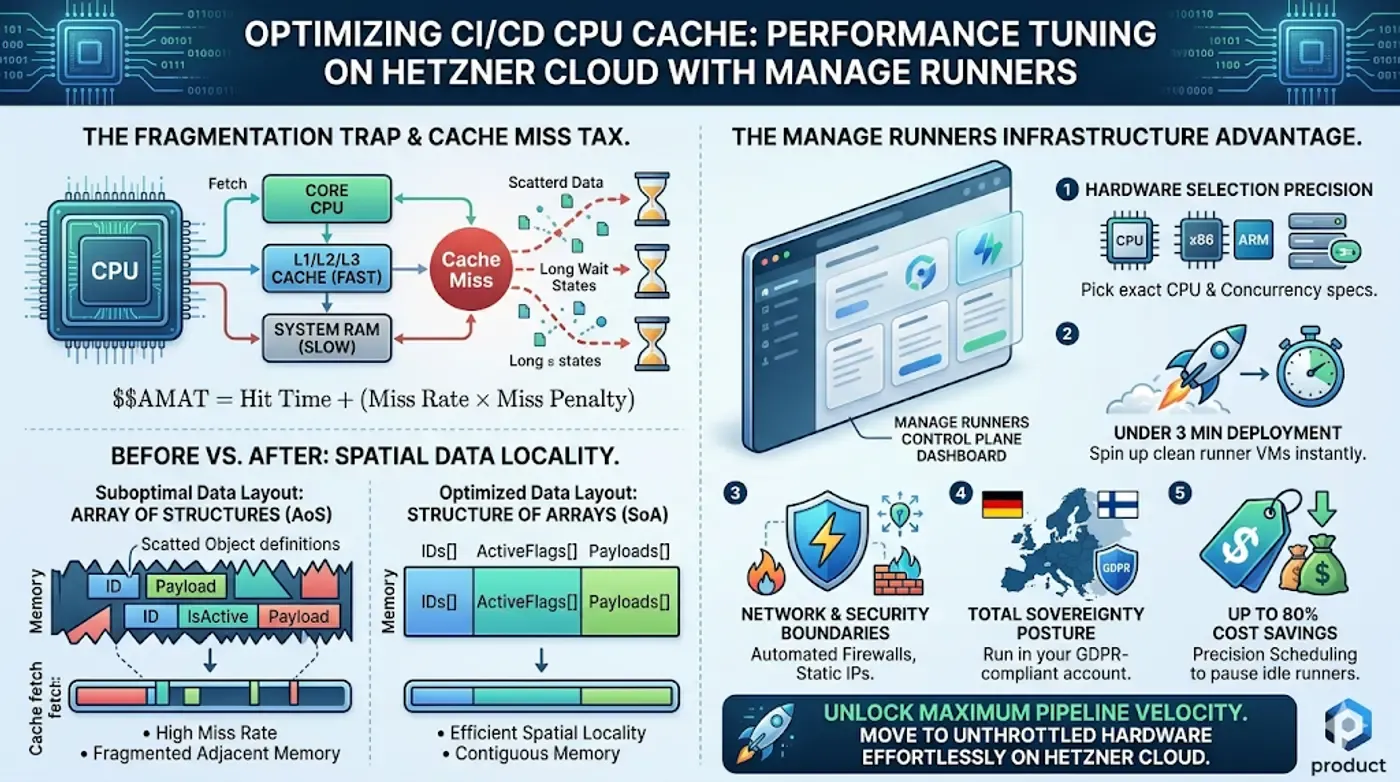
Modern execution systems rely on a layered memory hierarchy. While system RAM provides large-scale memory storage, its fetch times are incredibly slow compared to core execution speeds. To protect the processing pipelines, processors look to an on-chip CPU cache layered into L1, L2, and L3 pools.
When a test loop attempts to read data, the memory controller pulls an entire 64-byte block (a cache line) into the L1 container. If the next variable your code requires resides right next to the previous one in memory, the hardware logs a "cache hit" and executes instantly. If your data structure uses arbitrary pointer-chasing arrays, the next variable must be fetched all the way from system RAM. This triggers a "cache miss," forcing your execution threads into thousands of idle wait states.
We can track this processing penalty via the Average Memory Access Time equation:
AMAT = Hit Time + (Miss Rate * Miss Penalty)
Even a 5% increase in your cache miss rate can double your effective memory access time, quietly draining your pipeline efficiency during dense integration test suites.
2. The Fragmentation Trap: Array of Structures (AoS) vs. Structure of Arrays (SoA)
A common culprit for cache eviction in heavy testing loops is unoptimized data placement. Object-Oriented layouts often construct an Array of Structures (AoS), which scatters isolated field variables randomly across system memory addresses.
To maximize spatial data locality, software engineers apply memory-oriented performance tuning by shifting data fields into a Structure of Arrays (SoA). This ensures that processing loops can parse contiguous memory chunks sequentially without constantly clearing adjacent cache lines.
// Suboptimal: Array of Structures (AoS) - Triggers high cache eviction
type TestUser struct {
ID uint64 // 8 bytes
IsActive bool // 1 byte (leads to padding fragmentation)
Payload [512]byte // 512 bytes
}
var users []TestUser // Loop parsing 'IsActive' evicts cache lines rapidly
// Optimized: Structure of Arrays (SoA) - High spatial cache locality
type OptimizedUserCluster struct {
IDs []uint64
ActiveFlags []bool // Contiguous block parsed efficiently by the CPU cache
Payloads [][512]byte
}3. Manage Runners: Hardware Selection Customization for Heavy CI Workloads
Fixing code-level fragmentation yields minimal results if your shared cloud environment forces high hypervisor context switching. Manage Runners provides a centralized, automated platform to launch and scale dedicated GitLab runners directly on Hetzner Cloud, offering the raw hardware focus your pipelines need.
Our specialized dashboard allows you to select exact compute specs to support deep micro-architectural optimizations:
- Hardware Selection Precision: Pick specific CPU architectures and concurrency layouts directly to match the spatial execution paths of your performance tuning strategies.
- Under 3 Minutes Deployment: Spin up clean, dedicated runner virtual machines instantly straight from a modern glassmorphism-inspired UI.
- Network & Security Boundaries: Every runner receives a permanent Static IP address and automated Hetzner Firewalls mapped via labels to protect external asset access.
- Total Sovereignty Posture: Run tasks safely inside your own GDPR-compliant Hetzner account (Germany/Finland). For absolute code isolation, Manage Runners maintains no SSH access to your runner VMs.
By running your optimized workflows on unthrottled hardware and using our native precision scheduling to automatically pause runners when developers are offline, your engineering teams can reduce monthly cloud bills by up to 80% while restoring reliable performance to your continuous integration engine.
4. Conclusion
Unoptimized data mapping creates severe computing barriers at scale. Moving your pipelines to dedicated computing paths and structuring code loops around direct silicon data pathways removes memory latency and secures rapid software execution.
Ready to unlock unthrottled pipeline throughput? [Optimize your Performance Tuning with Manage Runners] and achieve effortless hardware control on Hetzner Cloud.