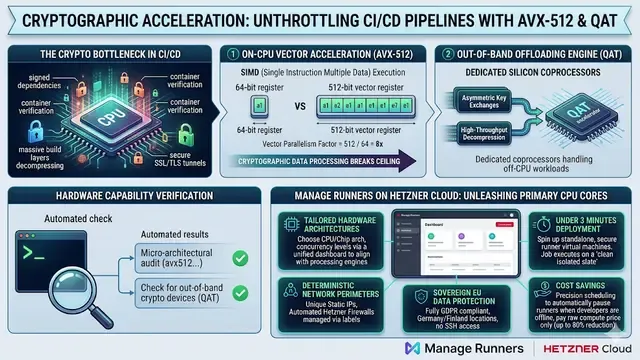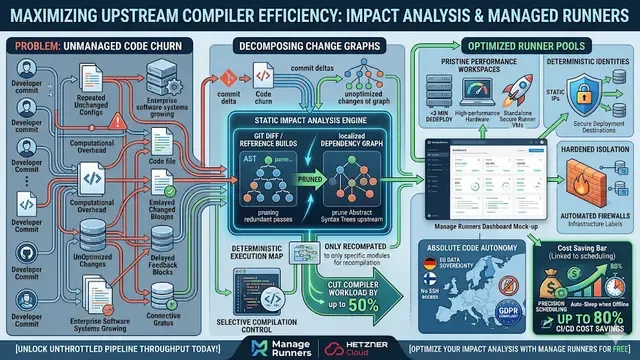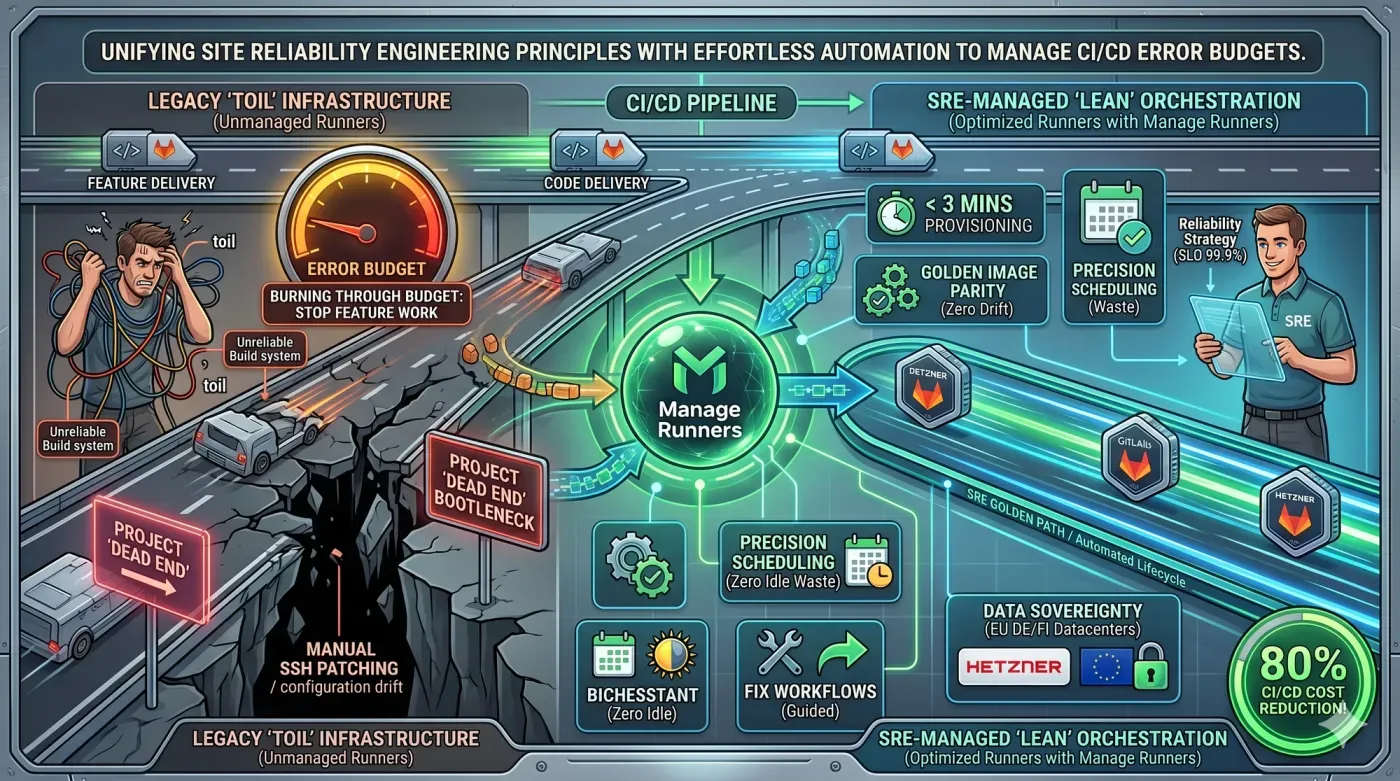
In the 2026 engineering landscape, your build system is no longer just a "tool", it is production infrastructure. If your pipelines are down, your developers are idle, and your release cycle grinds to a halt. Transitioning toward Site Reliability Engineering (SRE) for your CI/CD fleet is the only way to ensure the build system never becomes a "dead end." By treating runners with the same rigor as user-facing services, teams can balance the need for rapid feature delivery with the absolute requirement for platform stability.
1. Defining the SLI and SLO for CI/CD
In Site Reliability Engineering, we start with Service Level Indicators (SLIs) and Service Level Objectives (SLOs). For a runner fleet, the "Golden Signals" differ slightly from traditional web services. You should measure:
- Availability: Is a runner ready when a job is triggered?
- Latency (Queue Time): How long does a job sit in "Pending"?
- Efficiency: Are we over-provisioned and wasting budget?
Once these are defined, you set an SLO (e.g., "99.9% of jobs must start in under 60 seconds"). This leads directly to the core of SRE decision-making: the error budget.
2. Managing the Error Budget of Your Build Fleet
The Error budget is the "slack" between perfect reliability and your SLO. It represents the acceptable level of failure. If your runners are frequently in an "Error" state due to unpatched dependencies or manual configuration drift, you are burning through your budget.
When the budget is exhausted, SRE principles dictate that you stop feature work and focus entirely on reliability. In a CI/CD context, this means if your runners are failing, your team must stop pushing code and start fixing the infrastructure.
# Example: Calculating remaining Error Budget (Simplified)
# Total Allowed Unreliability - Actual Unreliability = Remaining Budget
# 0.1% (Uptime Goal) - 0.04% (Current Downtime) = 0.06% (Safe to deploy changes)3. Eliminating "Toil" Through Automation
A primary goal of Site Reliability Engineering is the reduction of "toil" repetitive, manual tasks that provide no long-term value. Manually SSH-ing into runner VMs to "fix" a broken Docker daemon is the definition of toil. It is inconsistent, unscalable, and eats into your Error budget by introducing human error.
Modern SRE thinking replaces manual intervention with automated lifecycle management. Instead of repairing a broken runner, you should discard it and provision a clean, standardized instance in minutes.
4. Manage Runners: The SRE Orchestrator for GitLab
Manage Runners was built specifically to enable Site Reliability Engineering for teams running on Hetzner Cloud. We provide the automation layer required to maintain high SLOs without the operational overhead.
- Automated "Fix" Workflows: Stop the manual toil. Our guided workflows handle common deployment issues, like GitLab token validation failures, automatically.
- Precision Provisioning: Spin up a high-performance runner in less than 3 minutes. Whether you need Docker, Shell, or DinD, the environment is created identically every time, preventing configuration drift.
- Cost-Aware Reliability: Sustainability is an SRE concern. Use our native scheduling to pause runners during idle periods, reclaiming up to 80% of your CI/CD budget without sacrificing performance.
- Security & Sovereignty: Maintain total control. Runners are hosted in your own EU-based Hetzner account. We have no SSH access to your VMs, ensuring your infrastructure meets the highest governance standards.
By leveraging Manage Runners, you move beyond the "DIY" runner headache and enter a state of automated, high-performance orchestration that keeps your build fleet active and your developers productive.
5. Conclusion
Reliability is a feature, not an afterthought. By applying Site Reliability Engineering principles and strictly monitoring your error budget, you ensure that your CI/CD system remains a high-velocity highway rather than a dead end.
Ready to automate your reliability? [Experience SRE-grade orchestration with Manage Runners] and build a faster, more resilient pipeline.